Data: The heart of AI drug discovery
May 23, 2023
Delivering breakthrough biologics to patients requires data from the wet lab and the clinic — a lot of it.

ChatGPT is a remarkable technology that demonstrates the impact that generative AI could have on our lives. It’s also a useful tool for explaining to patients, partners, investors, and even our family and friends what we do at Absci.
In the simplest terms, Absci is building the ChatGPT of biologic drug discovery. But instead of generating text in response to a prompt, Absci generates biologic drug candidates in response to a disease target. Where it typically takes ten years and a billion dollars to bring one new drug to market, generative AI — combined with our ultra-high-throughput screening platform — enables us to create and validate millions of antibody candidates in a matter of weeks, which may shorten the timeline to market. That has the potential to transform the drug industry and help us achieve our mission to bring better biologics to patients faster.
While those two applications of generative AI are completely different, there is one way in which ChatGPT and our AI platform are very much alike: They both depend on massive amounts of training data to be effective. In the case of ChatGPT, that involves reading just about everything ever published digitally and in print. In the case of Absci, to create effective drugs, we need massive amounts of data from protein sequences, structures, and the clinic.
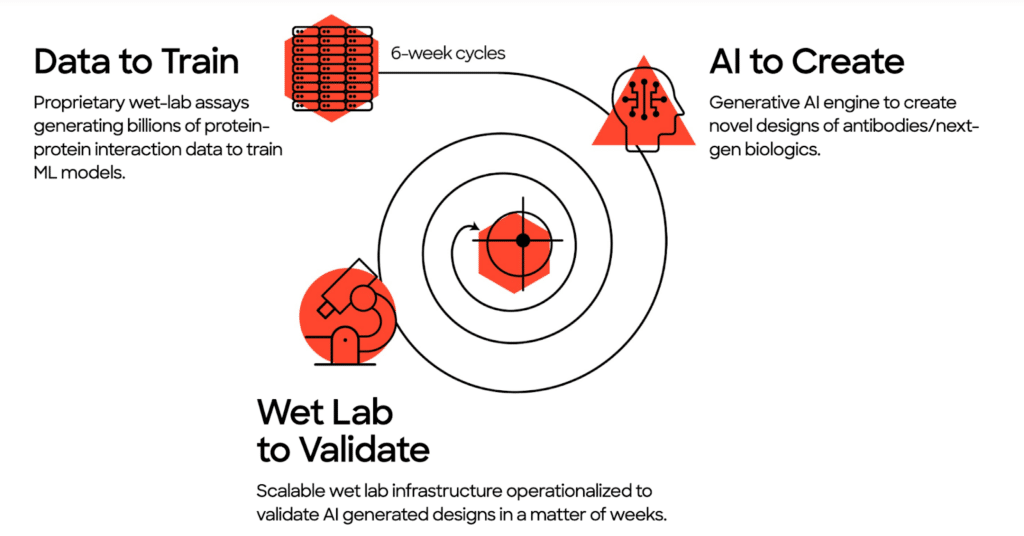
The wet lab data pipeline
Put simply, to have the best AI drug creation platform, you need the best data. To that end, Absci is working to build the world’s premiere data pipeline for AI drug discovery.
There are several public sources of data that are a useful basis from which to begin. These include The Protein Data Bank (protein structures), SAbDab (antibody/antigen complex structures), Observed Antibody Space (antibody sequences), and databases of protein structure like UniProt. AlphaFold, one of the latest and greatest tools for predicting protein structure from sequence, itself uses deep learning AI methods. The use of these and other open-source datasets are table stakes for both traditional discovery and AI drug creation.
Absci builds on public data with our own experimental wet lab data. Our multiplex synthetic biology approach overcomes the limitations of today’s highest-throughput automation labs to create training data at an unprecedented speed, quality, and volume. It has the ability to design and test millions of AI-designed antibodies every week, and that dynamic data is extremely attractive compared to the large but static sample banks of traditional drug discovery.
Absci’s scalable wet lab is a defining feature of AI drug creation and what really sets us apart. Our proprietary wet lab assays generate the massive amounts of biological data needed to enable the predictive power of machine learning. Then, we use that data to design, test, and run experiments in silico (on the computer rather than at a lab bench). This dramatically speeds up the hit finding process to discover unique, generative variants that could never be found using standard methods.
The clinical data pipeline
Besides designing and validating potential therapeutic antibodies for a potential disease target, there’s another aspect to drug discovery: finding and selecting the right target in the first place. As our Chief Innovation Officer and pharma veteran Andreas Busch puts it: “You can produce the best antibody against pretty much any epitope imaginable… But if your target is off, it’s worth nothing.”
That’s where clinical data comes into play. Clinical data is vital to target selection. Absci uses clinical datasets to identify novel antibodies from patients with exceptional immune responses. (For example, antibodies derived from cancer patients with remarkable immune responses have been instrumental in developing targeted cancer therapies.) Then, using our reverse immunology approach, Absci computationally re-assembles antigen-antibody pairs as promising potential starting points for drug development.
But access to clinical data is challenging. That’s because many data sources are owned by companies or institutions that may be reluctant to share their patient-consented research data with others. This can make it difficult for researchers and pharmaceutical companies to access the data they need to develop new drugs, particularly if they do not have the resources to conduct their own clinical trials or studies.
To bring clinical insights to AI drug creation, Absci is partnering with several leading institutions. Together, these data partnerships give Absci a robust clinical data pipeline that enables our AI platform across a wide range of therapeutic areas. They will also help build Absci’s internal therapeutic pipeline:
- St. John’s Cancer Institute (SJCI) is a pioneer in cancer care, research and innovation. In February 2023, SJCI and Absci announced a partnership leveraging SJCI’s leading cancer biospecimen repository and molecular database to uncover breakthrough cancer therapies.
- Aster Insights is a leading oncology data organization with the most advanced lifetime-consented clinicogenomics data to accelerate discovery research. In April 2023, Absci announced it would use Aster’s multi-institutional data set to accelerate the creation of therapeutics for a range of malignancies and patient profiles.
- The University of Oxford’s Kennedy Institute of Rheumatology, a leading biomedical research center for chronic inflammatory and musculoskeletal conditions, announced in May 2023 a partnership with Absci to create breakthrough therapies for immune-mediated diseases. Absci will identify novel antibodies from patients with exceptional immune responses to inflammatory bowel disease (IBD), then reverse engineer promising antibody therapy candidates.
With this incredible clinical data pipeline, we can start to focus our AI drug creation engine on the best possible targets.
A data turning point for pharma
Generative AI is an extremely powerful tool, but it requires massive amounts of high quality data to be effective. That’s true whether you’re using it to craft your emails or creating de novo versions of all three heavy chain CDRs (HCDR123), the antibody regions most critical to target binding. In either case, the old saying applies: “garbage in, garbage out.” Absci is solving the data problem in pharma, first using synthetic biology to generate vast biological data for AI-designed therapeutic candidates, and also with the clinical data to effectively target diseases.
Biotech R&D is at an inflection point. With the emergence of AI drug creation, the industry sees the huge value of data at each step in the drug discovery and development process. Innovators who adopt a systematic data-first approach early on will have a huge advantage in the coming AI transformation toward more efficient and effective drug creation.
More importantly, if we can make this turn as an industry, we are taking a big step toward the holy grail of precision medicine, which rests on the notion of using more and more refined clinical parameters and more and more refined genetic information on patients coming from smaller and smaller patient populations. Ultimately, this is how we will tailor treatments to extremely specific patient populations — perhaps to the individual level.
Data is the key to AI drug creation, both today and tomorrow. We think it’s a huge opportunity, both for our industry and for the patients we aim to serve.